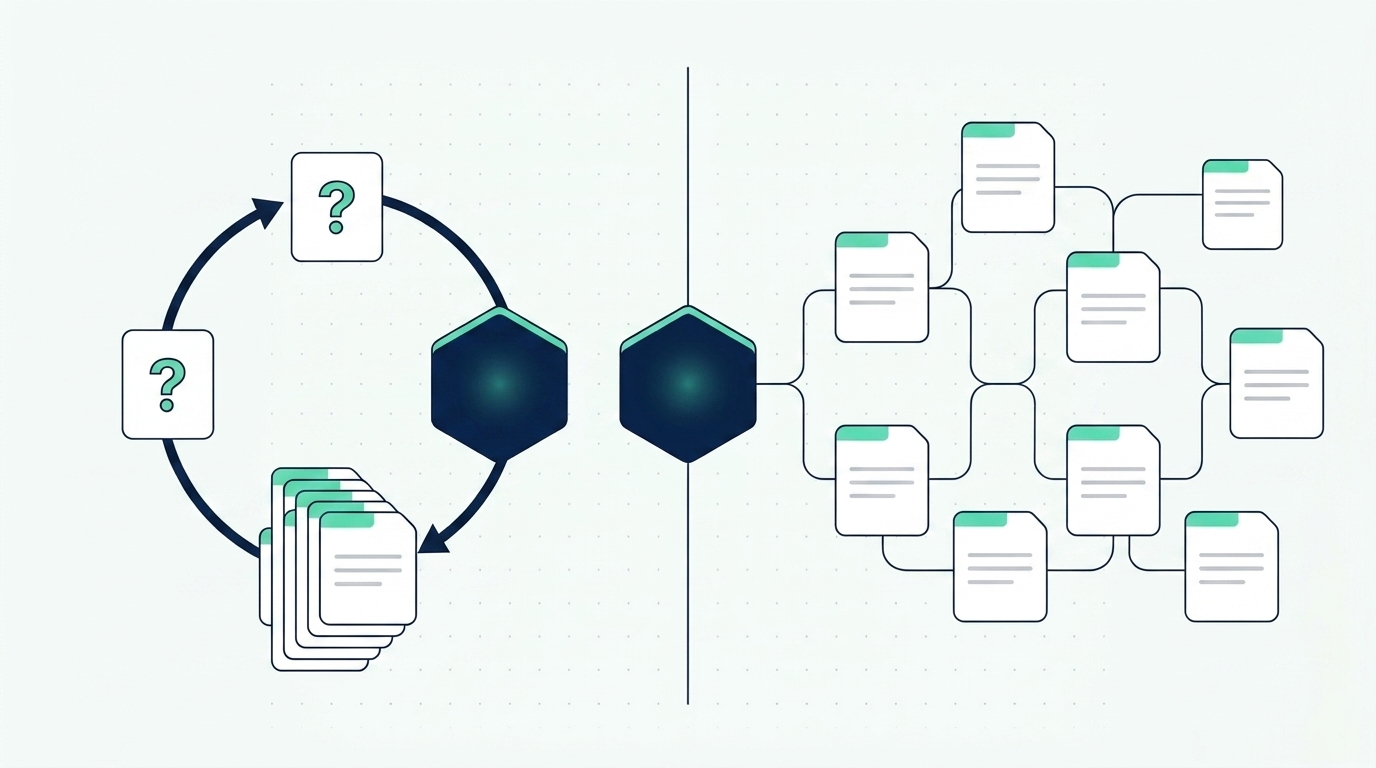
LLM Wiki vs RAG: la differenza in una frase
La differenza tra LLM Wiki e RAG sta nel momento in cui l’AI fa il lavoro cognitivo. Il RAG (Retrieval-Augmented Generation) recupera frammenti di documenti e ragiona su di essi a ogni singola domanda. La LLM Wiki sintetizza e collega la conoscenza una volta sola, in fase di ingestione, e poi consulta pagine già pronte. In pratica: il RAG privilegia la freschezza del dato, la LLM Wiki privilegia la coerenza e il costo.
Capire questa distinzione è il primo passo per scegliere l’architettura giusta — o per capire quando servono entrambe.
Come funziona il RAG
Il RAG collega un modello linguistico ai dati interni dell’azienda. A ogni domanda, il sistema cerca i passaggi più pertinenti in un indice (tipicamente vettoriale), li inietta nel prompt come contesto e lascia che il modello generi la risposta citando le fonti.
Il vantaggio è la freschezza: il sistema legge sempre l’ultima versione dei documenti, anche se cambiano ogni minuto. Il limite è che, a ogni query, il modello riparte da zero: recupera frammenti grezzi, ne ricostruisce le relazioni e sintetizza una conclusione che poi scompare. Non c’è accumulo: la stessa fatica si ripete identica a ogni domanda. Per vedere il RAG all’opera, abbiamo raccolto diversi esempi e casi d’uso reali.
Come funziona la LLM Wiki
La LLM Wiki ribalta la prospettiva. Quando una nuova fonte entra nel sistema, un agente AI la legge, la riassume e aggiorna le pagine correlate della wiki: entità, concetti, confronti. Il lavoro di sintesi avviene una volta, in fase di ingestione, e il risultato resta scritto.
Quando poi fai una domanda, l’agente non deve ricostruire nulla: i collegamenti tra documenti esistono già, le contraddizioni sono già state segnalate, la sintesi riflette già tutto ciò che è stato ingerito. Il vantaggio è la coerenza e un costo per query più basso; il limite è che la wiki funziona al meglio su basi di conoscenza di dimensioni gestibili e che cambiano con frequenza moderata.
Il confronto, dimensione per dimensione
| Dimensione | RAG | LLM Wiki |
|---|---|---|
| Quando avviene la sintesi | A ogni query | Una volta, in ingestione |
| Freschezza del dato | Alta (legge sempre l’ultima versione) | Dipende dall’ultima ingestione |
| Coerenza tra documenti | Ricostruita ogni volta | Già consolidata nelle pagine |
| Costo per query | Più alto (recupero + ragionamento) | Più basso (consulta pagine pronte) |
| Scala dei dati | Molto grande, anche milioni di documenti | Moderata (centinaia di pagine) |
| Dati in tempo reale | Ideale | Meno adatto |
| Trasparenza | Citazioni ai frammenti | Pagine sintetiche tracciabili |
Quando scegliere il RAG
Il RAG è la scelta giusta quando:
- i dati sono troppi per entrare nel contesto del modello (cataloghi prodotto, basi documentali enormi, anni di ticket);
- le informazioni cambiano in tempo reale (prezzi, disponibilità, normative aggiornate di continuo);
- ti serve sempre e comunque l’ultima versione del documento, senza margine di ritardo.
Pensa a un assistente per il supporto clienti che interroga migliaia di articoli in continuo aggiornamento: qui il recupero a tempo di query è insostituibile.
Quando scegliere la LLM Wiki
La LLM Wiki dà il meglio quando:
- la base di conoscenza ha dimensioni gestibili e cambia con frequenza moderata;
- servono coerenza e sintesi tra documenti diversi, non solo il recupero del singolo frammento;
- vuoi che la conoscenza si accumuli invece di essere ricostruita ogni volta.
Documentazione di prodotto, processi interni, conoscenza di progetto, materiale di onboarding: sono tutti casi in cui avere pagine già sintetizzate e collegate vale più della freschezza al secondo.
Due scenari per capire la scelta
La teoria diventa chiara con due esempi opposti.
Scenario A — Supporto clienti su un catalogo enorme. Un’azienda con migliaia di prodotti, schede tecniche aggiornate di continuo e anni di ticket. Le informazioni cambiano ogni giorno e sono troppe per stare nel contesto di un modello. Qui la scelta è il RAG: a ogni domanda recupera l’ultima versione del documento giusto, senza il rischio di rispondere con dati superati. Una LLM Wiki, in questo caso, farebbe fatica a stare al passo con gli aggiornamenti.
Scenario B — Onboarding e processi interni. La stessa azienda vuole un assistente che spieghi ai nuovi assunti procedure, decisioni storiche e modo di lavorare. Questa conoscenza è di dimensioni gestibili, cambia di rado e ha bisogno soprattutto di coerenza e sintesi tra documenti diversi. Qui la LLM Wiki è ideale: pagine già collegate, contesto già consolidato, costo per domanda più basso.
È la stessa azienda, ma due esigenze opposte. Ed è il motivo per cui, nella pratica, la domanda giusta non è “quale dei due è meglio?” ma “quale serve per questo caso d’uso?”.
E il fine-tuning?
Una terza via spesso citata è il fine-tuning, cioè il riaddestramento del modello sui propri dati. È un’opzione potente ma rigida: costosa, statica e difficile da aggiornare ogni volta che i dati cambiano. Sia il RAG sia la LLM Wiki lasciano il modello intatto e gli forniscono la conoscenza dall’esterno, restando molto più semplici da aggiornare e da governare. Per la maggior parte dei casi d’uso aziendali sulla conoscenza interna, il fine-tuning non è la prima scelta.
La risposta più frequente: usarli insieme
Nella pratica enterprise, LLM Wiki e RAG non sono alternative esclusive. L’approccio più solido è ibrido:
- la LLM Wiki fornisce la conoscenza sintetizzata e coerente sui temi stabili (processi, prodotti, decisioni storiche);
- il RAG copre i dati voluminosi o in tempo reale (ticket, log, cataloghi);
- un orchestratore decide, in base alla domanda, da quale livello attingere — o da entrambi.
Nell’ecosistema Microsoft questo si traduce, ad esempio, in una LLM Wiki su file markdown versionati affiancata da un livello RAG su Azure OpenAI e Azure AI Search, il tutto dentro il perimetro di sicurezza aziendale.
Come si progetta un’architettura ibrida
Il cuore di un sistema ibrido è l’orchestratore: il componente che, ricevuta una domanda, decide a quale livello attingere. La logica, semplificando, è questa:
- se la domanda riguarda temi stabili (un processo, una decisione storica, “come funziona X da noi”), attinge alla LLM Wiki, dove la conoscenza è già sintetizzata;
- se riguarda dati voluminosi o freschi (un ticket recente, un prezzo, un documento specifico tra milioni), interroga il RAG;
- per domande complesse può combinare entrambi, usando la wiki per il contesto e il RAG per il dettaglio puntuale.
Progettare bene questo livello di smistamento è ciò che distingue un sistema solido da uno che dà risposte incoerenti. Non è un dettaglio implementativo: è la decisione architetturale che determina qualità, costo e affidabilità dell’intero assistente.
Gli errori più comuni nella scelta
Nella pratica, gli errori che vediamo più spesso non riguardano la tecnologia in sé, ma il modo in cui viene scelta.
- Scegliere per moda, non per caso d’uso. Adottare il RAG perché “lo fanno tutti” o la LLM Wiki perché è il pattern del momento, senza partire dai dati e dalle domande reali, porta a sistemi costosi e inadatti.
- Sottovalutare la frequenza di aggiornamento. Costruire una wiki su dati che cambiano ogni ora significa rincorrere continuamente l’ultima versione. È l’errore di architettura più frequente.
- Sovradimensionare. Mettere in piedi un’infrastruttura RAG complessa per una base di conoscenza che entrerebbe comodamente nel contesto di un modello: si paga di più per gestire una complessità che non serve.
- Ignorare i permessi. Qualsiasi sia l’architettura, un sistema che recupera documenti riservati e li mostra a chi non dovrebbe vederli è un problema di sicurezza, non una funzionalità.
- Trattare la scelta come definitiva. Le esigenze cambiano: spesso si parte da un approccio e si evolve verso l’ibrido. Progettare con questa flessibilità in mente evita di doversi rifare da capo.
La buona notizia è che nessuno di questi errori riguarda i modelli: riguardano l’analisi che viene prima. Ed è lì che conviene investire tempo — o farsi affiancare da chi questi sistemi li costruisce.
Come scegliere, in concreto
La decisione non è ideologica, è ingegneristica: dipende da volume dei dati, frequenza di aggiornamento, budget per query e requisiti di coerenza. Sbagliare architettura significa pagare di più per risultati peggiori — un sistema RAG dove bastava una wiki, o una wiki dove servivano freschezza e scala.
In Dev4Side progettiamo entrambe le architetture e quelle ibride, integrate con Microsoft 365 e Azure — come nel caso di Sveva.ai, l’agente AI che trasforma i dati aziendali in insight via linguaggio naturale. Se vuoi capire quale approccio fa al caso tuo, parla con un nostro esperto: partiamo dai tuoi dati e dai tuoi casi d’uso, non dalla tecnologia.
Domande frequenti
Qual è la differenza principale tra LLM Wiki e RAG? Il momento in cui avviene la sintesi. Il RAG recupera e ragiona sui documenti a ogni query (a tempo di esecuzione); la LLM Wiki sintetizza e collega la conoscenza una volta sola in fase di ingestione, mantenendo pagine già pronte. Il RAG privilegia la freschezza, la LLM Wiki la coerenza e il costo.
Quando conviene usare il RAG invece della LLM Wiki? Quando i dati sono molti (oltre quelli che entrano nel contesto del modello) o cambiano in tempo reale: cataloghi, ticket, prezzi, normative aggiornate di continuo. In questi casi il recupero a tempo di query del RAG è la scelta giusta.
Quando conviene la LLM Wiki? Quando la base di conoscenza ha dimensioni gestibili e cambia con frequenza moderata, e quando servono coerenza, sintesi tra documenti e collegamenti già pronti: documentazione di prodotto, processi interni, conoscenza di progetto, onboarding.
LLM Wiki e RAG si possono combinare? Sì, ed è spesso la soluzione migliore in azienda. La LLM Wiki fornisce la conoscenza sintetizzata e coerente per i temi stabili, mentre il RAG copre i dati voluminosi o in tempo reale. Un orchestratore sceglie quale usare in base alla domanda.
Che differenza c’è con il fine-tuning? Il fine-tuning riaddestra il modello sui propri dati: costoso, statico e difficile da aggiornare. Sia RAG sia LLM Wiki lasciano il modello intatto e gli forniscono la conoscenza dall’esterno, restando molto più semplici da aggiornare e da governare.
Scritto da
Davide Mazzoli
Modern AI Apps · Dev4Side
Dev4Side Software · Microsoft Gold Partner
Hai bisogno di implementare questo nella tua azienda?
I nostri team specializzati hanno completato oltre 200 implementazioni Microsoft in tutta Italia. Contattaci per una valutazione gratuita e senza impegno del tuo progetto.
Articoli correlati
LLM Wiki: cos'è e come funziona la knowledge base che si aggiorna da sola
La LLM Wiki è la knowledge base che un agente AI costruisce e aggiorna da solo dai tuoi documenti. Cos'è, come funziona e come portarla in azienda.
Azure OpenAI RAG: l’approccio enterprise alla generative AI
Vediamo come la combinazione della tecnologia RAG con Azure Open AI può aiutare a costruire i modelli intelligenti di cui la propria azienda ha bisogno.
Esempi di RAG: casi d'uso e aziende che possono beneficiarne
RAG in azienda: la Retrieval Augmented Generation connette l'AI ai dati interni dell'impresa. Esempi pratici e casi d'uso reali per PMI e grandi imprese.