LLM Wiki vs RAG: differences and when to choose each
LLM Wiki and RAG compared: how they work, costs, accuracy and when to choose one, the other or a hybrid approach. A practical guide for businesses.
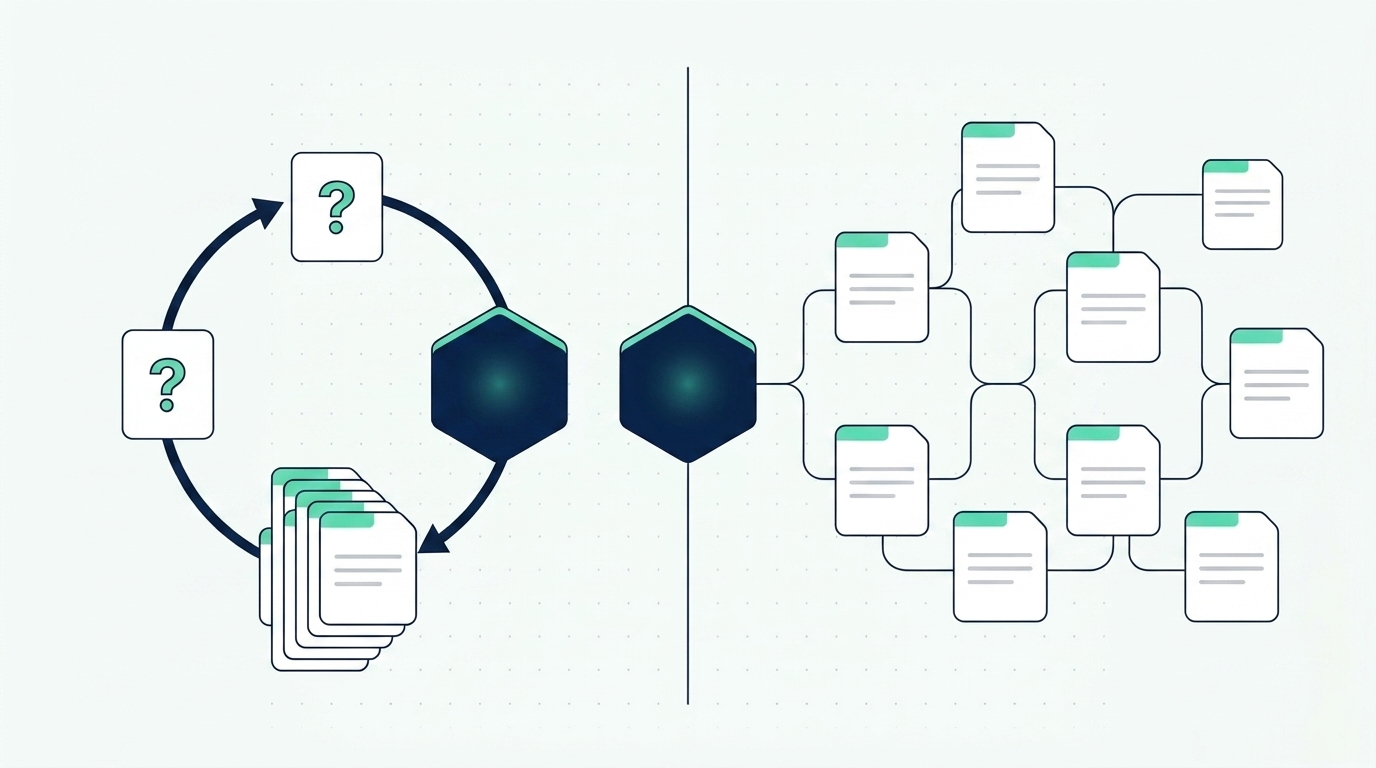
LLM Wiki vs RAG: the difference in one sentence
The difference between LLM Wiki and RAG lies in when the AI does the cognitive work. RAG (Retrieval-Augmented Generation) retrieves fragments of documents and reasons over them at every single question. The LLM Wiki synthesizes and links knowledge just once, during ingestion, and then consults ready-made pages. In practice: RAG favors the freshness of the data, the LLM Wiki favors consistency and cost.
Understanding this distinction is the first step toward choosing the right architecture, or toward recognizing when you need both.
How RAG works
RAG connects a language model to a company’s internal data. For every question, the system searches an index (typically a vector index) for the most relevant passages, injects them into the prompt as context, and lets the model generate an answer that cites its sources.
The advantage is freshness: the system always reads the latest version of the documents, even if they change every minute. The limitation is that, at every query, the model starts from scratch: it retrieves raw fragments, reconstructs the relationships between them, and synthesizes a conclusion that then disappears. Nothing accumulates: the same effort is repeated identically for every question. To see RAG in action, we have collected several real-world examples and use cases.
How the LLM Wiki works
The LLM Wiki flips the perspective. When a new source enters the system, an AI agent reads it, summarizes it and updates the related pages of the wiki: entities, concepts, comparisons. The synthesis work happens once, during ingestion, and the result stays written down.
When you later ask a question, the agent has nothing to reconstruct: the links between documents already exist, contradictions have already been flagged, and the synthesis already reflects everything that has been ingested. The advantage is consistency and a lower cost per query; the limitation is that the wiki works best on knowledge bases of manageable size that change at a moderate pace.
The comparison, dimension by dimension
| Dimension | RAG | LLM Wiki |
|---|---|---|
| When synthesis happens | At every query | Once, during ingestion |
| Data freshness | High (always reads the latest version) | Depends on the last ingestion |
| Cross-document consistency | Reconstructed each time | Already consolidated in the pages |
| Cost per query | Higher (retrieval + reasoning) | Lower (consults ready-made pages) |
| Data scale | Very large, even millions of documents | Moderate (hundreds of pages) |
| Real-time data | Ideal | Less suitable |
| Transparency | Citations to fragments | Traceable synthesized pages |
When to choose RAG
RAG is the right choice when:
- the data is too large to fit in the model’s context (product catalogs, huge document bases, years of tickets);
- the information changes in real time (prices, availability, constantly updated regulations);
- you always need the latest version of the document, with no margin for delay.
Think of a customer support assistant that queries thousands of continuously updated articles: here, query-time retrieval is irreplaceable.
When to choose the LLM Wiki
The LLM Wiki is at its best when:
- the knowledge base is of manageable size and changes at a moderate pace;
- you need consistency and synthesis across different documents, not just retrieval of a single fragment;
- you want knowledge to accumulate instead of being reconstructed every time.
Product documentation, internal processes, project knowledge, onboarding material: these are all cases where having pages that are already synthesized and linked is worth more than freshness to the second.
Two scenarios to understand the choice
The theory becomes clear with two opposite examples.
Scenario A — Customer support on a huge catalog. A company with thousands of products, continuously updated datasheets and years of tickets. The information changes every day and is too extensive to fit in a model’s context. Here the choice is RAG: for every question it retrieves the latest version of the right document, with no risk of answering with outdated data. An LLM Wiki, in this case, would struggle to keep up with the updates.
Scenario B — Onboarding and internal processes. The same company wants an assistant that explains procedures, historical decisions and ways of working to new hires. This knowledge is of manageable size, changes rarely and above all needs consistency and synthesis across different documents. Here the LLM Wiki is ideal: pages already linked, context already consolidated, a lower cost per question.
It is the same company, but two opposite needs. And that is why, in practice, the right question is not “which of the two is better?” but “which one is needed for this use case?”.
What about fine-tuning?
A third path often mentioned is fine-tuning, that is, retraining the model on your own data. It is a powerful but rigid option: costly, static and hard to update every time the data changes. Both RAG and the LLM Wiki leave the model untouched and feed it knowledge from the outside, staying much simpler to update and to govern. For most enterprise use cases involving internal knowledge, fine-tuning is not the first choice.
The most common answer: use them together
In enterprise practice, LLM Wiki and RAG are not mutually exclusive alternatives. The most robust approach is hybrid:
- the LLM Wiki provides synthesized, consistent knowledge on stable topics (processes, products, historical decisions);
- RAG covers voluminous or real-time data (tickets, logs, catalogs);
- an orchestrator decides, based on the question, which layer to draw from, or both.
In the Microsoft ecosystem this translates, for example, into an LLM Wiki built on versioned markdown files alongside a RAG layer on Azure OpenAI and Azure AI Search, all within the company’s security perimeter.
How to design a hybrid architecture
The heart of a hybrid system is the orchestrator: the component that, upon receiving a question, decides which layer to draw from. The logic, simplified, is this:
- if the question concerns stable topics (a process, a historical decision, “how X works at our company”), it draws from the LLM Wiki, where the knowledge is already synthesized;
- if it concerns voluminous or fresh data (a recent ticket, a price, a specific document among millions), it queries RAG;
- for complex questions it can combine both, using the wiki for context and RAG for the precise detail.
Designing this routing layer well is what distinguishes a robust system from one that gives inconsistent answers. It is not an implementation detail: it is the architectural decision that determines the quality, cost and reliability of the entire assistant.
The most common mistakes in choosing
In practice, the mistakes we see most often are not about the technology itself, but about how it is chosen.
- Choosing by trend, not by use case. Adopting RAG because “everyone is doing it” or the LLM Wiki because it is the pattern of the moment, without starting from real data and real questions, leads to costly and unsuitable systems.
- Underestimating the update frequency. Building a wiki on data that changes every hour means constantly chasing the latest version. It is the most frequent architectural mistake.
- Over-engineering. Setting up a complex RAG infrastructure for a knowledge base that would fit comfortably in a model’s context: you pay more to manage complexity you don’t need.
- Ignoring permissions. Whatever the architecture, a system that retrieves confidential documents and shows them to people who shouldn’t see them is a security problem, not a feature.
- Treating the choice as final. Needs change: you often start with one approach and evolve toward a hybrid one. Designing with this flexibility in mind avoids having to start over from scratch.
The good news is that none of these mistakes is about the models: they are about the analysis that comes first. And that is where it pays to invest time, or to be supported by those who build these systems.
How to choose, concretely
The decision is not ideological, it is engineering: it depends on data volume, update frequency, budget per query and consistency requirements. Choosing the wrong architecture means paying more for worse results, a RAG system where a wiki would have sufficed, or a wiki where freshness and scale were needed.
At Dev4Side we design both architectures and the hybrid ones, integrated with Microsoft 365 and Azure, as in the case of Sveva.ai, the AI agent that turns business data into insight through natural language. If you want to understand which approach fits your case, talk to one of our experts: we start from your data and your use cases, not from the technology.
Frequently asked questions
What is the main difference between LLM Wiki and RAG? The moment the synthesis happens. RAG retrieves and reasons over documents at every query (at runtime); the LLM Wiki synthesizes and links knowledge just once, during ingestion, keeping ready-made pages. RAG favors freshness, the LLM Wiki favors consistency and cost.
When is RAG a better choice than an LLM Wiki? When the data is extensive (more than fits in the model’s context) or changes in real time: catalogs, tickets, prices, constantly updated regulations. In these cases, RAG’s query-time retrieval is the right choice.
When is an LLM Wiki the better choice? When the knowledge base is of manageable size and changes at a moderate pace, and when you need consistency, cross-document synthesis and ready-made links: product documentation, internal processes, project knowledge, onboarding.
Can LLM Wiki and RAG be combined? Yes, and it is often the best solution in the enterprise. The LLM Wiki provides synthesized, consistent knowledge for stable topics, while RAG covers voluminous or real-time data. An orchestrator decides which one to use based on the question.
How does this differ from fine-tuning? Fine-tuning retrains the model on your own data: costly, static and hard to update. Both RAG and the LLM Wiki leave the model untouched and feed it knowledge from the outside, staying much simpler to update and to govern.
Written by
Davide Mazzoli
Modern AI Apps · Dev4Side
Dev4Side Software · Microsoft Gold Partner
Need help implementing this in your company?
Our specialist teams have delivered 200+ Microsoft implementations across Italy. Contact us for a free, no-obligation evaluation of your project.
Related articles
LLM Wiki: what it is and how the self-updating knowledge base works
The LLM Wiki is the knowledge base an AI agent builds and updates on its own from your documents. What it is, how it works and how to bring it in-house.
Azure OpenAI RAG: the enterprise approach to generative AI
Azure OpenAI RAG combines GPT with enterprise data for accurate AI responses. Architecture patterns, implementation steps, and business benefits explained.
Examples of RAG: use cases and companies that can benefit from it
RAG explained with real examples: how Retrieval Augmented Generation connects AI to your company data and which industries and business types benefit most.